Optimización de Tablas y Transformaciones Avanzadas
Tratamiento de datos II
Bienvenidos y bienvenidas a Estación R
Hoja de Ruta - Módulo I
📌 Optimización de Tablas y Transformaciones Avanzadas
📦 Paquete {dplyr}
🔧 distinct()
🔧 pull()
🔧 relocate()
🔧 coalesce()
🔧 na_if()
🔧 slice()📦 Paquete {tidyr}
🔧 pivot_longer()
🔧 pivot_wider() 📦 Paquete {janitor}
🔧 clean_names() 🔧 tabyll() Configuración para esta clase
✅ Armar un proyeto de trabajo
✅ Crear una carpeta llamada
datos✅ Descargar la base de Ingreso de anual de Personas 2024 - MX y ubicarla en la carpeta
datos✅ Crear un script de trabajo
Configuración para esta clase
- Código para cargar la base directo desde Github, sin tener que descargarla (se necesita conexión a internet)
Procesamiento de datos - Mapa
Procesamiento de datos - La pipa (o tubería)
- EL PIPE
 - > Una forma de escribir
- > Una forma de escribir
Procesamiento de datos - La pipa (o tubería)

Procesamiento de datos - Buenas prácticas
- Diagnosticar
- Procesar
- Chequear
Procesamiento de datos - Buenas prácticas
- Ejemplo: Nombre de columnas
Procesamiento de datos - Buenas prácticas
- Ejemplo: Categorías de una variable
[1] "Guadalajara" "Monterrey" "PUEBLA" "Puebla" "CDMX"
[6] "guadalajara" "Querétaro" "GUADALAJARA" "MONTERREY" "puebla"
[11] "monterrey" Pregunta
🗳 Votar: ¿Qué hace la función str_to_title()?
[1] "Pepe Locura" "Rodobolfo Lanzini" "Lola Lala" - 𝐀 –> Agrega una mayúscula a la primera letra de la primera palabra
- 𝐁 –> Agrega una mayúscula a la primera letra de todas las palabras
- 𝐂 –> Pasa todo a minúscula
Procesamiento de datos
📚 Kit de funciones:
🪛 janitor::clean_names(): Simplifica y estandariza nombres de columnas.
🪛 dplyr::distinct(): Filtra y mantiene solo filas únicas según variables específicas.
🪛 dplyr::pull(): Extrae una columna como vector.
Procesamiento de datos
📚 Kit de funciones:
🪛 dplyr::coalesce(): Ayuda a manejar valores faltantes reemplazándolos con valores específicos.
🪛 dplyr::na_if(): Convierte valores específicos (por ejemplo valores erróneos) a NA.
🪛 dplyr::slice(): Selecciona subconjuntos específicos de filas según su posición.
Procesamiento de datos
🪛 distinct(): Filtra y mantiene solo filas únicas según variables específicas.
### Diagnóstico
# Identifico si existen casos duplicados
df_duplicados <- df_ingresos_trab %>%
get_dupes()
head(df_duplicados, n = 3)# A tibble: 3 × 6
nombre_persona edad_persona ciudad_residencia ingreso_anual nivel_educativo
<chr> <dbl> <chr> <dbl> <chr>
1 Sofía 49 Monterrey 54512 Primario incomple…
2 Sofía 49 Monterrey 54512 Primario incomple…
3 Sofía 49 Monterrey 54512 Primario incomple…
# ℹ 1 more variable: dupe_count <int>Procesamiento de datos
🪛 distinct(): Filtra y mantiene solo filas únicas según variables específicas.
### Procesamiento (elimino duplicados)
df_ingresos_trab <- df_ingresos_trab %>%
distinct()
### Chequeo
df_ingresos_trab %>%
get_dupes()# A tibble: 0 × 6
# ℹ 6 variables: nombre_persona <chr>, edad_persona <dbl>,
# ciudad_residencia <chr>, ingreso_anual <dbl>, nivel_educativo <chr>,
# dupe_count <int>Procesamiento de datos
¿Y si considero un caso “duplicado” sólo por dos de sus variables?
Procesamiento de datos
🪛 pull(): Extrae una columna como vector, facilitando ciertas operaciones.
Procesamiento de datos
🪛 pull(): Extrae una columna como vector, facilitando ciertas operaciones.
Procesamiento de datos
El ingreso máximo de la ciudad de Pueba es de $89.769
Procesamiento de datos
🪛 dplyr::coalesce(): Ayuda a manejar valores faltantes reemplazándolos con valores específicos.
Procesamiento de datos
Procesamiento de datos
🪛 dplyr::na_if(): Convierte valores específicos (por ejemplo valores erróneos) a NA.
–> Útil cuando ciertos códigos o textos (como “NS/NC” o “Sin dato”) significan dato faltante.
na_if()
✅ Ejemplo 1 — Texto “NS/NC” → NA
na_if()
✅ Ejemplo 1 — Texto “NS/NC” → NA
na_if()
✅ Ejemplo 1 — Texto “NS/NC” → NA
na_if()
✅ Ejemplo 1— Texto “NS/NC” y “Sin dato” → NA
📦 La familia de funciones slice()
| Función | ¿Qué hace? |
|---|---|
slice_head() |
Devuelve las primeras x filas del data frame (o de cada grupo si se usa group_by()). |
slice_tail() |
Devuelve las últimas x filas del data frame (o de cada grupo). |
slice_min() |
Devuelve las filas con los valores mínimos de la columna col. |
slice_max() |
Devuelve las filas con los valores máximos de la columna col. |
slice_sample() |
Selecciona x filas de forma aleatoria (útil para crear muestras). |
📦 La familia de funciones slice()
# A tibble: 9 × 5
nombre_persona edad_persona ciudad_residencia ingreso_anual nivel_educativo
<chr> <dbl> <chr> <dbl> <chr>
1 María 32 Guadalajara 0 Universitario inc…
2 Juan 55 Guadalajara 0 Universitario com…
3 Luis 37 Monterrey 39255 Primario completo
4 Sofía 36 Puebla 0 <NA>
5 Pedro 55 Puebla 0 Universitario com…
6 Ana 49 Puebla 0 Primario completo
7 Ana 29 Cdmx 38580 Universitario com…
8 Juan 59 Querétaro 0 Universitario com…
9 Carlos 46 Querétaro 0 Sin dato 📦 La familia de funciones slice()
¿Y qué pasa si usamos los parámetros with_ties = TRUE y n =?
📦 La familia de funciones slice()
¿Y qué pasa si usamos los parámetros with_ties = TRUE y n =?
📦 La familia de funciones slice()
🧠 Extra: ¿cuándo usar slice() y no filter()?
✔️ Cuando se quiere trabajar por posición y no por condición lógica.
✔️ Cuando se necesita una muestra o los valores extremos por grupo.
❌ Si se necesita filtrar por edad, provincia o texto, usar filter().
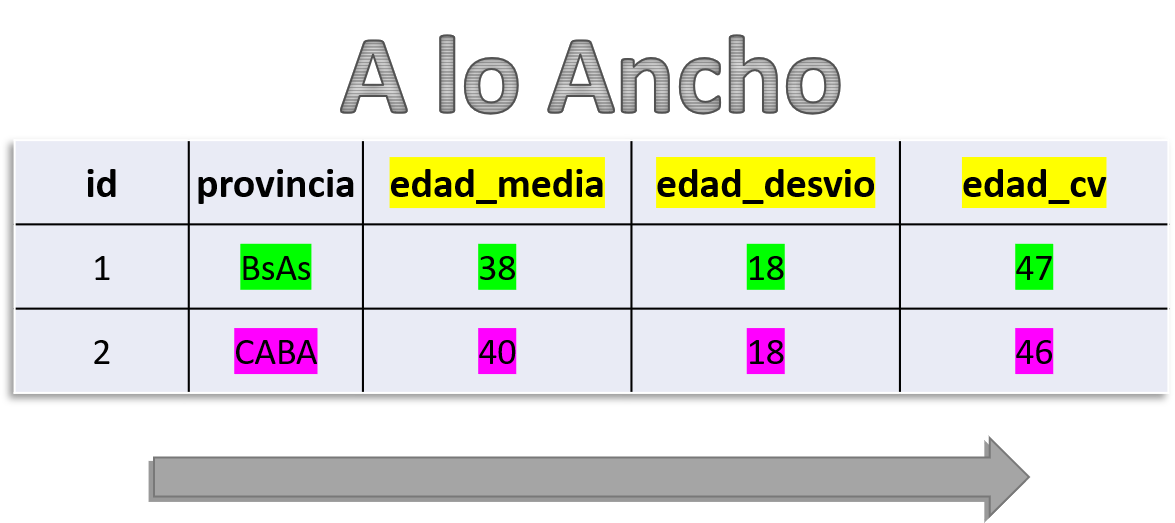
🔄 De ancho a largo y de largo a ancho
Funciones pivot_longer() y pivot_wider()
¿Qué es pivotear una tabla?
Pivotear significa reorganizar columnas en filas o filas en columnas, sin perder información.
🔁 Es una transformación estructural, no de contenido.
🟦 Formato ancho: muchas columnas → 1 fila por caso
🟥 Formato largo: menos columnas → varias filas por caso
🔄 De ancho a largo y de largo a ancho

Ejemplo práctico
Evolución del turismo receptivo, emisivo y el saldo de viajes de turistas, según medio de transporte utilizado y región de destino/origen, en formato serie de tiempo. Corresponde al total país.
¿Está a lo ancho o a lo largo?
# A tibble: 3 × 82
indice_tiempo emisivo_aerea_bolivia emisivo_aerea_europa emisivo_aerea_chile
<date> <dbl> <dbl> <dbl>
1 2016-01-01 4196 32038 28185
2 2016-02-01 6287 43823 28663
3 2016-03-01 4249 45705 25517
# ℹ 78 more variables: emisivo_aerea_paraguay <dbl>,
# emisivo_aerea_brasil <dbl>, emisivo_aerea_ee_uu_y_canada <dbl>,
# emisivo_aerea_resto_de_america <dbl>, emisivo_aerea_resto_del_mundo <dbl>,
# emisivo_aerea_uruguay <dbl>, emisivo_terrestre_bolivia <dbl>,
# emisivo_terrestre_europa <dbl>, emisivo_terrestre_chile <dbl>,
# emisivo_terrestre_paraguay <dbl>, emisivo_terrestre_brasil <dbl>,
# emisivo_terrestre_ee_uu_y_canada <dbl>, …pivot_longer() – de ancho a largo
pivot_longer() – de ancho a largo
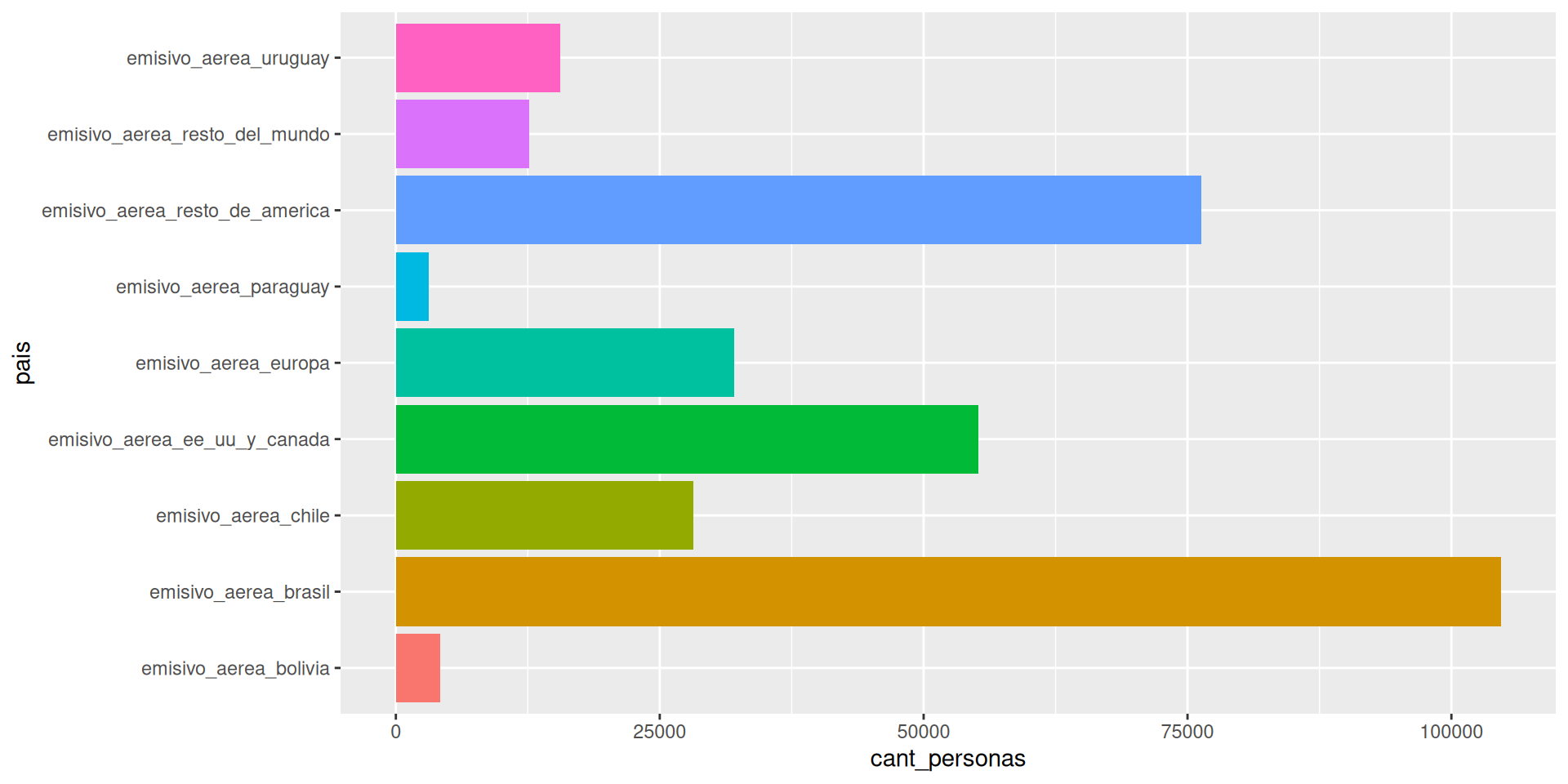
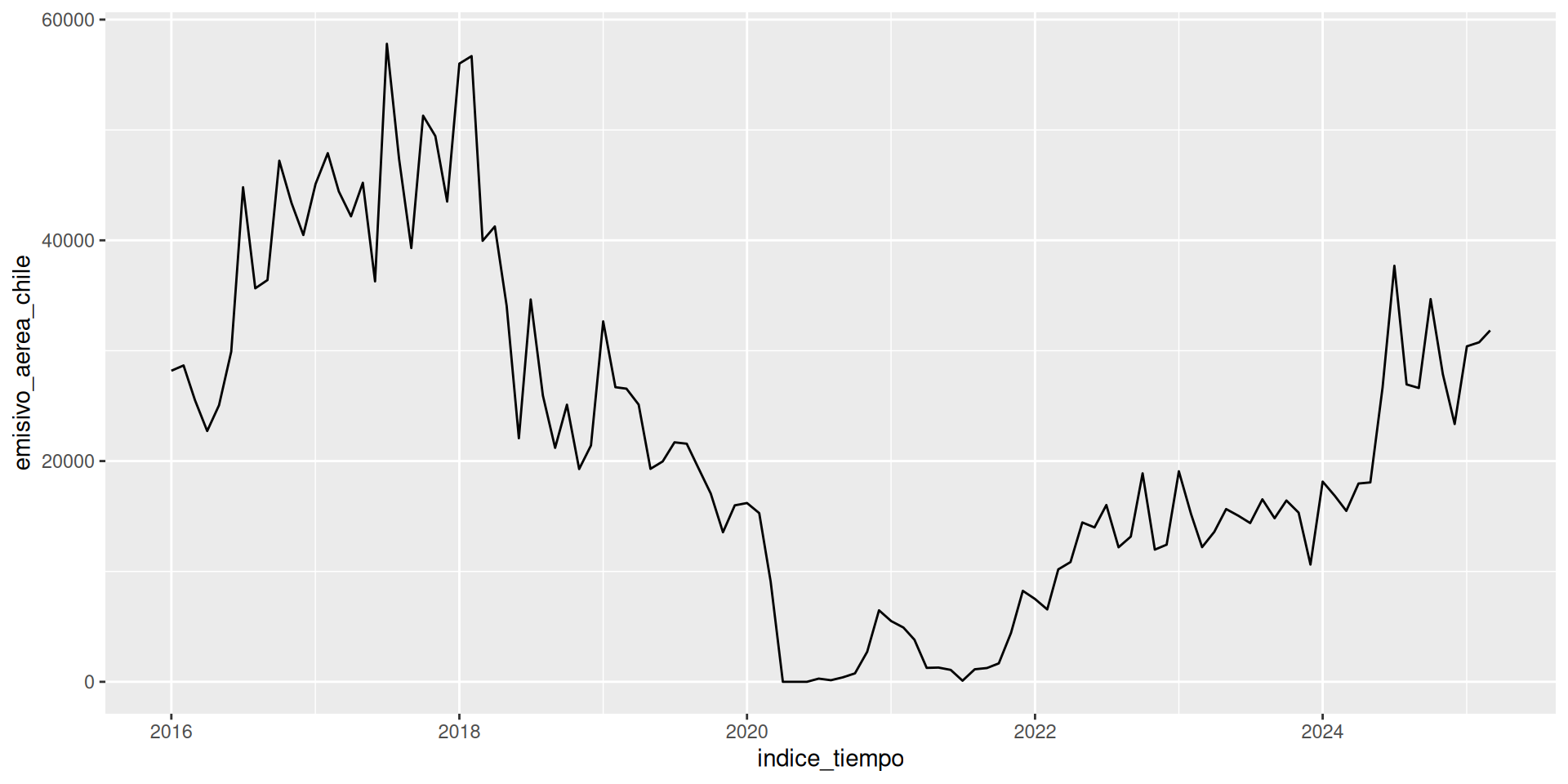
Preparo la base para analizar turismo emisivo aereo por país
df_emisivo_aereo <- df_turismo %>%
select(indice_tiempo, starts_with("emisivo_aerea"))
head(df_emisivo_aereo, n = 3)# A tibble: 3 × 10
indice_tiempo emisivo_aerea_bolivia emisivo_aerea_europa emisivo_aerea_chile
<date> <dbl> <dbl> <dbl>
1 2016-01-01 4196 32038 28185
2 2016-02-01 6287 43823 28663
3 2016-03-01 4249 45705 25517
# ℹ 6 more variables: emisivo_aerea_paraguay <dbl>, emisivo_aerea_brasil <dbl>,
# emisivo_aerea_ee_uu_y_canada <dbl>, emisivo_aerea_resto_de_america <dbl>,
# emisivo_aerea_resto_del_mundo <dbl>, emisivo_aerea_uruguay <dbl>pivot_longer() – de ancho a largo
### Cargo librería
library(tidyr)
tabla_ancha <- df_emisivo_aereo %>%
pivot_longer(cols = starts_with("emisivo_aerea"),
names_to = "pais",
values_to = "cant_personas")
head(tabla_ancha, n = 5)# A tibble: 5 × 3
indice_tiempo pais cant_personas
<date> <chr> <dbl>
1 2016-01-01 emisivo_aerea_bolivia 4196
2 2016-01-01 emisivo_aerea_europa 32038
3 2016-01-01 emisivo_aerea_chile 28185
4 2016-01-01 emisivo_aerea_paraguay 3093
5 2016-01-01 emisivo_aerea_brasil 104681pivot_longer() – de ancho a largo
¿Cuándo necesitaría “pivotear”?
pivot_longer() – de ancho a largo
hacer un poco más que pivotear…
df_emisivo_aereo %>%
pivot_longer(cols = starts_with("emisivo_aerea"),
names_to = "pais",
values_to = "cant_personas",
names_prefix = "emisivo_aerea_")# A tibble: 999 × 3
indice_tiempo pais cant_personas
<date> <chr> <dbl>
1 2016-01-01 bolivia 4196
2 2016-01-01 europa 32038
3 2016-01-01 chile 28185
4 2016-01-01 paraguay 3093
5 2016-01-01 brasil 104681
6 2016-01-01 ee_uu_y_canada 55222
7 2016-01-01 resto_de_america 76330
8 2016-01-01 resto_del_mundo 12649
9 2016-01-01 uruguay 15601
10 2016-02-01 bolivia 6287
# ℹ 989 more rowspivot_longer() – de ancho a largo
hacer un poco más que pivotear…
df_emisivo_aereo %>%
pivot_longer(cols = starts_with("emisivo_aerea"),
names_to = "pais",
values_to = "cant_personas",
names_prefix = "emisivo_aerea_") %>%
mutate("pais" = str_replace_all(pais, "_", " "),
"pais" = str_to_title(pais),
"pais" = str_replace_all(pais, "Ee Uu", "EEUU"))# A tibble: 999 × 3
indice_tiempo pais cant_personas
<date> <chr> <dbl>
1 2016-01-01 Bolivia 4196
2 2016-01-01 Europa 32038
3 2016-01-01 Chile 28185
4 2016-01-01 Paraguay 3093
5 2016-01-01 Brasil 104681
6 2016-01-01 EEUU Y Canada 55222
7 2016-01-01 Resto De America 76330
8 2016-01-01 Resto Del Mundo 12649
9 2016-01-01 Uruguay 15601
10 2016-02-01 Bolivia 6287
# ℹ 989 more rowspivot_longer() – de ancho a largo
¿Cuándo necesitaría “pivotear”?
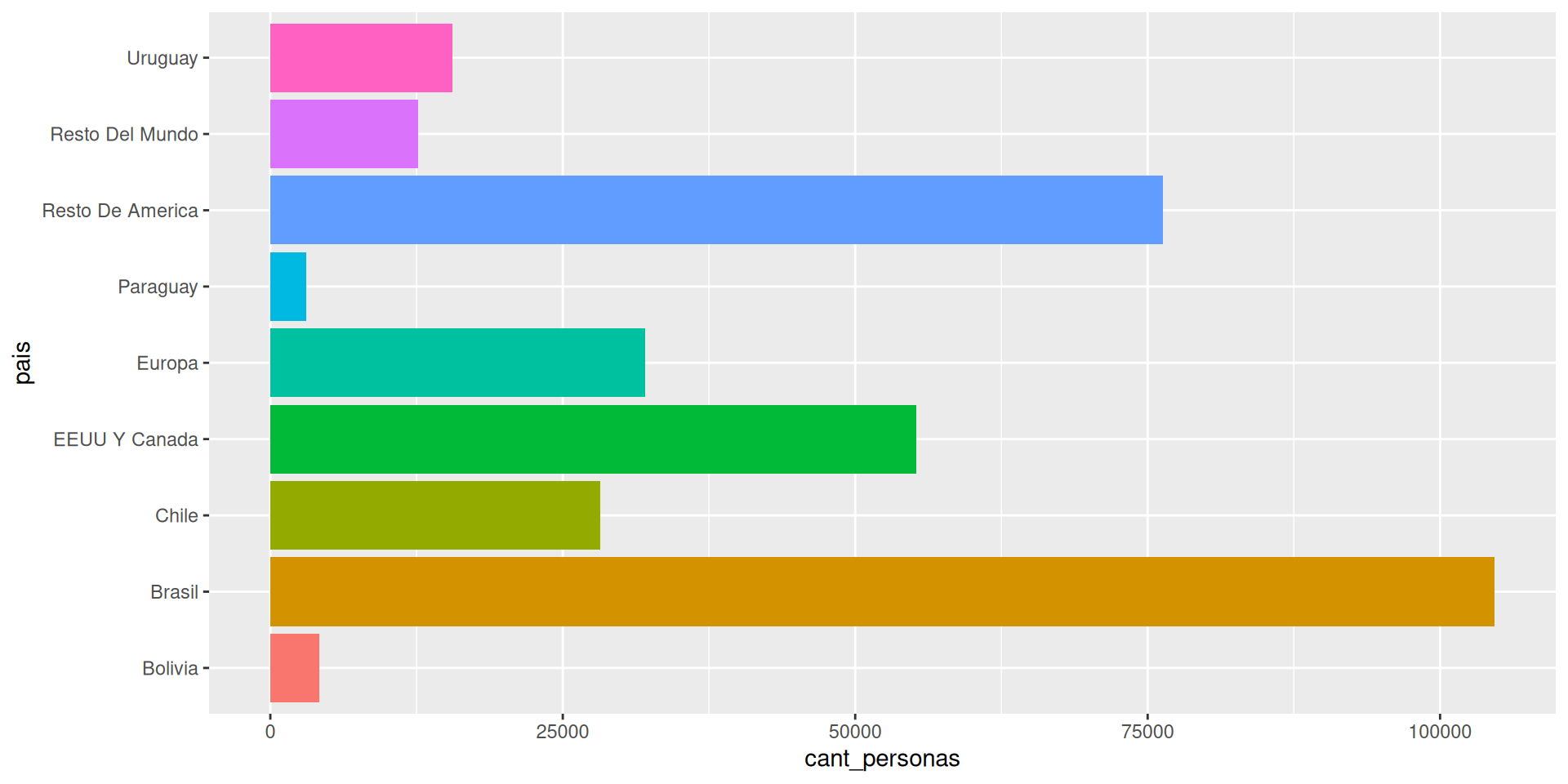
pivot_wider() – de largo a ancho
# A tibble: 999 × 3
indice_tiempo pais cant_personas
<date> <chr> <dbl>
1 2016-01-01 emisivo_aerea_bolivia 4196
2 2016-01-01 emisivo_aerea_europa 32038
3 2016-01-01 emisivo_aerea_chile 28185
4 2016-01-01 emisivo_aerea_paraguay 3093
5 2016-01-01 emisivo_aerea_brasil 104681
6 2016-01-01 emisivo_aerea_ee_uu_y_canada 55222
7 2016-01-01 emisivo_aerea_resto_de_america 76330
8 2016-01-01 emisivo_aerea_resto_del_mundo 12649
9 2016-01-01 emisivo_aerea_uruguay 15601
10 2016-02-01 emisivo_aerea_bolivia 6287
# ℹ 989 more rowspivot_wider() – de largo a ancho
# A tibble: 111 × 10
indice_tiempo emisivo_aerea_bolivia emisivo_aerea_europa emisivo_aerea_chile
<date> <dbl> <dbl> <dbl>
1 2016-01-01 4196 32038 28185
2 2016-02-01 6287 43823 28663
3 2016-03-01 4249 45705 25517
4 2016-04-01 3201 44351 22725
5 2016-05-01 2899 59681 25059
6 2016-06-01 2355 77750 29914
7 2016-07-01 3731 73738 44808
8 2016-08-01 3907 73131 35652
9 2016-09-01 3412 72818 36402
10 2016-10-01 3055 76781 47213
# ℹ 101 more rows
# ℹ 6 more variables: emisivo_aerea_paraguay <dbl>, emisivo_aerea_brasil <dbl>,
# emisivo_aerea_ee_uu_y_canada <dbl>, emisivo_aerea_resto_de_america <dbl>,
# emisivo_aerea_resto_del_mundo <dbl>, emisivo_aerea_uruguay <dbl>pivot_wider() – de largo a ancho
![]()